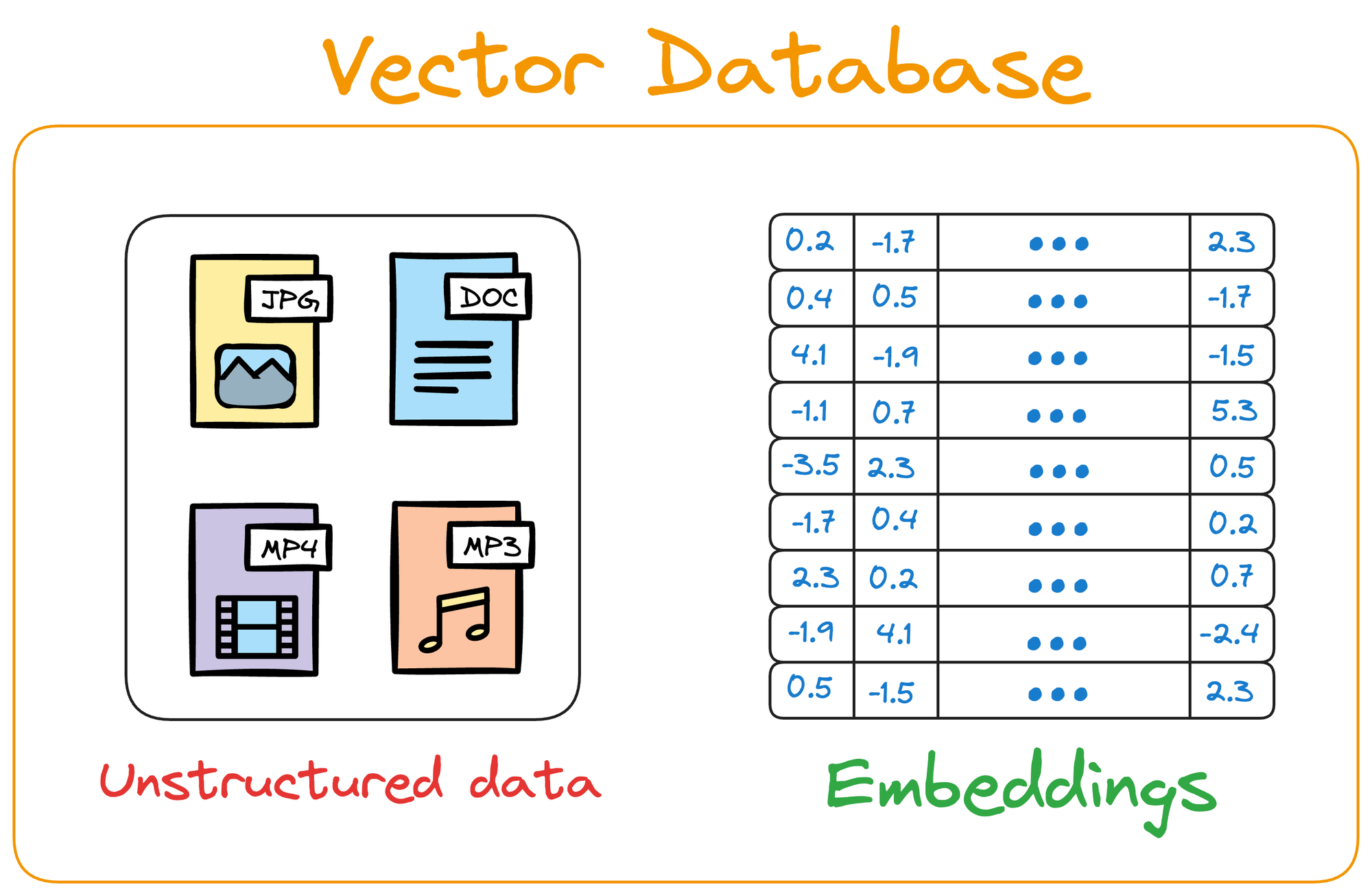
Why Vector Databases Were Born
Traditional databases like SQL are designed to handle exact or partial matches using string-based operations like
LIKE '%car%'. These queries are effective when looking for literal matches, but they fall short when
we want to find conceptually related information. For instance, searching for "car" won't return "wheel", "engine",
or "steering wheel", even though these concepts are closely related.
Limitations of Text-Based Queries
While SQL and NoSQL systems work well with structured, keyword-based data, they are not optimized for semantic search — that is, retrieving information based on meaning rather than exact wording.
Embeddings: A Semantic Representation of Meaning
This is where embeddings come into play. Instead of representing text as strings, we use machine learning models to encode it into high-dimensional vectors. These vectors are placed in a semantic space, where similar concepts are located near each other, even if their literal terms are completely different.
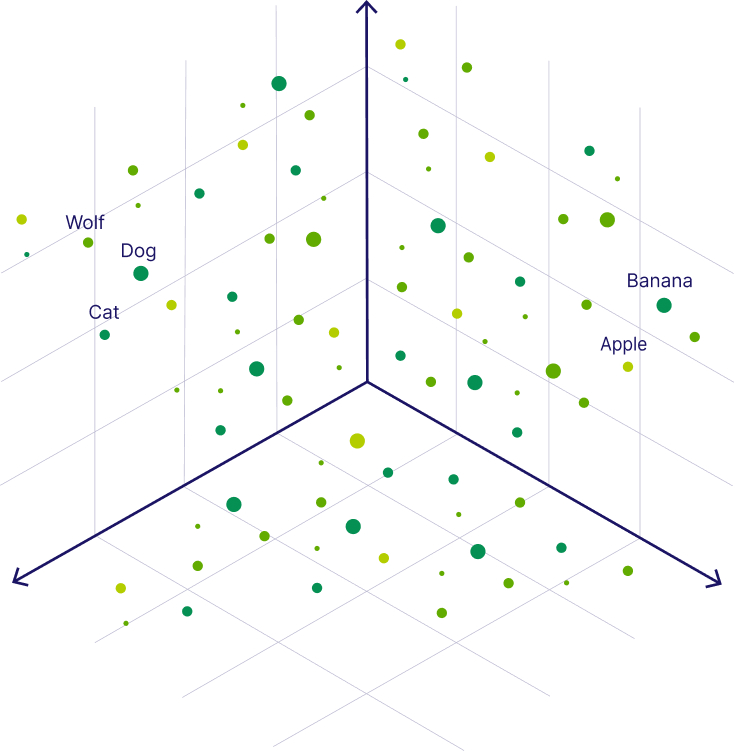
As a visual analogy, imagine plotting foods on a graph with two axes: one for "dessertness" and one for "sandwichness". Even though pizza and salad have very different ingredients, they may be close to each other in this particular space.

Why a New Kind of Database Was Needed
Once we represent data as embeddings, traditional databases are no longer enough. We need systems capable of performing operations like vector similarity search — finding which vectors are closest to a given input vector based on distance metrics like cosine similarity or Euclidean distance.

The Importance of Consistency Between Embedding Models
One critical aspect of working with vector databases is that the embeddings must be generated using the same model — or a model that is guaranteed to be compatible. This ensures that the relative positions of vectors remain meaningful. If you store vectors generated by Model A but later query using Model B, the results might be completely inaccurate, even if the text seems similar.
Conclusion
Vector databases emerged out of the need to search semantically — not just syntactically. As we move toward applications powered by natural language understanding, recommendation systems, and semantic search, vector databases offer a foundational layer for storing and querying meaning, not just strings.