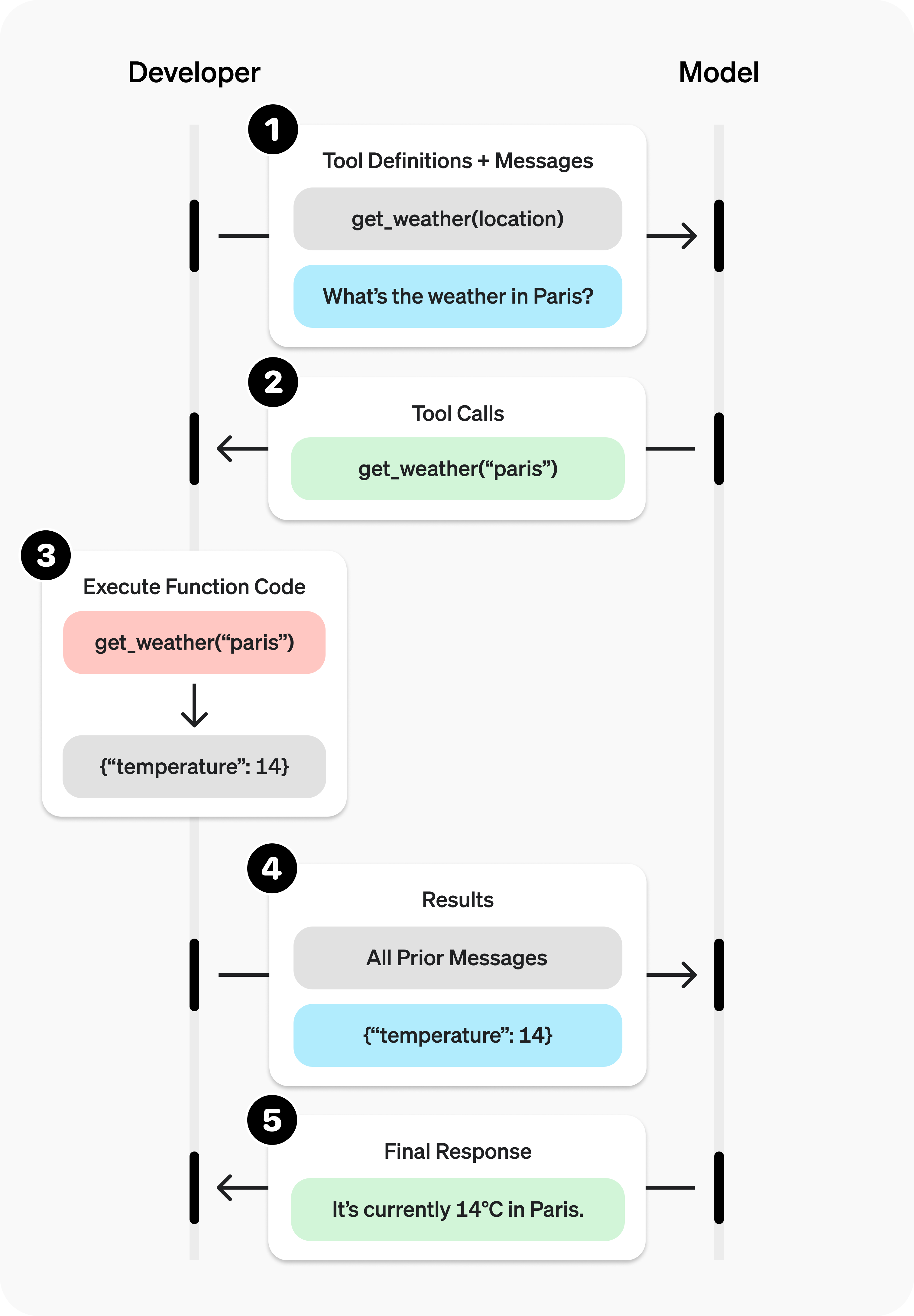
Tool Calling con OpenAI y Python: el flujo real
Orquestación backend explícita, sin magia ni ejecución implícita
Concepto clave
El modelo de lenguaje no ejecuta funciones. Solo devuelve una estructura indicando qué debería ejecutarse.
El backend en Python es quien: valida, ejecuta y controla.
Tool real (código ejecutable)
Esta función nunca se envía al modelo.
from datetime import datetime
def get_server_time():
return datetime.utcnow().isoformat()Declaración de la Tool (metadata)
Esto es lo único que OpenAI recibe.
tools = [
{
"type": "function",
"function": {
"name": "get_server_time",
"description": "Devuelve la hora actual del servidor",
"parameters": {
"type": "object",
"properties": {}
}
}
}
]Primera llamada al LLM
from openai import OpenAI
client = OpenAI()
messages = [
{"role": "user", "content": "¿Qué hora es en el servidor?"}
]
response = client.chat.completions.create(
model="gpt-4.1-mini",
messages=messages,
tools=tools
)El LLM solicita la Tool
{
finish_reason: "tool_calls",
tool_calls: [
{
name: "get_server_time",
arguments: {}
}
]
}Ejecución explícita de la Tool
tool_call = response.choices[0].message.tool_calls[0]
if tool_call.function.name == "get_server_time":
result = get_server_time()Reinyección del resultado (role=tool)
messages.append(response.choices[0].message)
messages.append({
"role": "tool",
"tool_call_id": tool_call.id,
"content": result
})Segunda llamada al LLM
final_response = client.chat.completions.create(
model="gpt-4.1-mini",
messages=messages
)
print(final_response.choices[0].message.content)Respuesta final
"La hora actual del servidor es 2025-12-18T03:10:00 UTC."Roles involucrados
- user: intención
- assistant: razonamiento
- tool: datos reales
Conclusión
Tool Calling es un patrón de orquestación backend, no una feature mágica del modelo.
El LLM sugiere. Python ejecuta. Vos controlás.