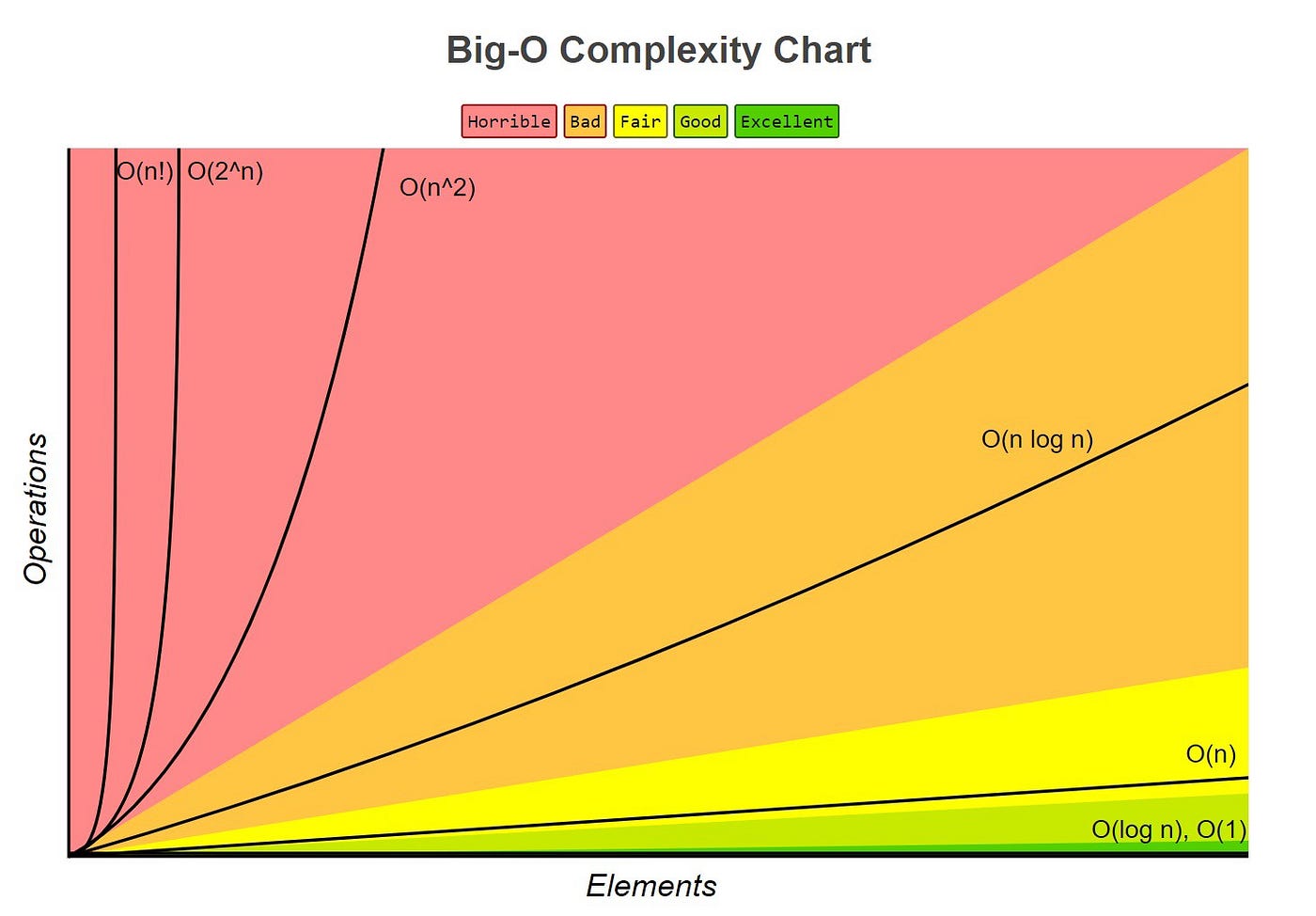
Notación Big O explicada con ejemplos en Python
Cómo describir el comportamiento de un algoritmo cuando crecen los datos de entrada. No medimos tiempo en segundos, sino cómo escala el costo a medida que la entrada se hace más grande.
La pregunta clave
¿Qué tan rápido empeora esto cuando los datos aumentan? Si duplico la entrada, ¿el algoritmo tarda el doble, mucho más, o lo mismo?
Qué medimos
Big O describe el peor caso y se enfoca en el crecimiento general, no en el tiempo exacto. Por eso ignoramos constantes y términos menores.
Regla de oro
Lo que importa es cómo escala, no cuánto tarda hoy. Un algoritmo lento con poca data puede ser malísimo con mucha data.
¿Qué es Big O?
La notación Big O se utiliza para describir cómo escala un algoritmo cuando crece la cantidad de datos de entrada. No mide tiempo exacto, sino el comportamiento general del algoritmo a medida que la entrada crece.
Big O se enfoca en el peor caso y elimina constantes innecesarias para quedarse
con lo importante: el crecimiento. Por eso decimos O(n)
en lugar de O(3n + 5).
Saber Big O nos ayuda a elegir el algoritmo correcto, anticipar problemas de performance y comunicar decisiones técnicas en una entrevista o en una review.
Constante
Acceso directoEl tiempo de ejecución no cambia sin importar el tamaño de la entrada. Siempre tarda lo mismo: 10 elementos, 1.000 o 1.000.000 dan igual.
Aparece cuando accedemos directamente a un valor sin recorrer estructuras, o cuando hacemos una operación que no depende del tamaño de los datos.
Ejemplo 1 · Acceder al primer elemento
Acceder por índice en una lista es siempre una operación de costo fijo.
def obtener_primero(lista):
return lista[0]
# Siempre 1 operacion: no importa si la lista tiene 10 o 10 millones
obtener_primero([5, 8, 12]) # -> 5Ejemplo 2 · Comparación simple
Una comparación directa siempre cuesta lo mismo, no depende de ninguna entrada grande.
def es_mayor(edad):
return edad >= 18
# Una comparacion: tiempo constante
es_mayor(25) # -> TrueLogarítmica
Divide y vencerásEsta complejidad aparece cuando en cada paso reducimos el problema a la mitad. Es extremadamente eficiente: si tenés un millón de elementos, sólo necesitás unas 20 operaciones.
El ejemplo clásico es la búsqueda binaria sobre una lista ordenada. Cada iteración descarta la mitad de los datos restantes.
Ejemplo 1 · Búsqueda binaria
En cada paso descartamos la mitad de la lista, por eso escala como log n.
def busqueda_binaria(lista, objetivo):
izq, der = 0, len(lista) - 1
while izq <= der:
medio = (izq + der) // 2
if lista[medio] == objetivo:
return True
elif lista[medio] < objetivo:
izq = medio + 1
else:
der = medio - 1
return False
# Para 1.000.000 de elementos solo necesita ~20 pasos
busqueda_binaria([1, 3, 5, 7, 9], 7) # -> TrueEjemplo 2 · Dividir hasta 1
Dividir n por 2 hasta llegar a 1 toma exactamente log₂(n) pasos.
def dividir_hasta_uno(n):
pasos = 0
while n > 1:
n //= 2
pasos += 1
return pasos
# 1024 -> 512 -> 256 -> ... -> 1 (10 pasos)
dividir_hasta_uno(1024) # -> 10Lineal
Un loopEl tiempo crece proporcionalmente a la cantidad de datos. Si duplicás los datos, duplicás el tiempo. Es lo que pasa cuando recorrés toda una lista una sola vez.
Es una complejidad totalmente aceptable en la mayoría de los casos. Procesar un array de N elementos no se puede hacer mejor que en O(n) si necesitás mirarlos todos.
Ejemplo 1 · Búsqueda lineal
Recorremos la lista hasta encontrar el objetivo, en el peor caso visitamos todos los elementos.
def buscar(lista, objetivo):
for x in lista:
if x == objetivo:
return True
return False
# Si la lista tiene 1000 elementos, el peor caso son 1000 comparaciones
buscar([3, 7, 12, 25], 12) # -> TrueEjemplo 2 · Suma de elementos
Para sumar todos los números de una lista necesitamos visitarlos a todos exactamente una vez.
def sumar(lista):
total = 0
for num in lista:
total += num
return total
# Si duplicas la lista, duplicas el tiempo: crece lineal
sumar([10, 20, 30, 40]) # -> 100Cuadrática
Loops anidadosSucede cuando hay loops anidados. Por cada elemento, recorrés todos los demás. Si tenés 1.000 elementos, hacés 1.000.000 de operaciones.
Funciona bien con listas chicas, pero se vuelve un problema serio cuando la entrada crece. Casi siempre se puede optimizar con estructuras como diccionarios o sets.
Ejemplo 1 · Todos los pares
Para cada elemento de la lista comparamos contra todos los demás, generando n × n combinaciones.
def pares(lista):
for i in lista:
for j in lista:
print(i, j)
# Con 1000 elementos genera 1.000.000 de prints
pares([1, 2, 3]) # 9 combinacionesEjemplo 2 · Buscar duplicados
Comparamos cada elemento con todos los siguientes. Es O(n²) aunque parezca menos por el i+1.
def duplicados(lista):
for i in range(len(lista)):
for j in range(i + 1, len(lista)):
if lista[i] == lista[j]:
return True
return False
# Con un set se puede resolver en O(n), mucho mas eficiente
duplicados([1, 2, 3, 2]) # -> TrueExponencial
Recursión combinatoriaEste es uno de los peores casos comunes. El número de operaciones se duplica con cada nuevo elemento. Con 30 elementos ya estamos hablando de más de mil millones de operaciones.
Aparece en problemas de combinaciones, subconjuntos o recursión sin optimización (sin memoización, sin podas). Casi siempre necesita ser reemplazado por programación dinámica.
Ejemplo 1 · Fibonacci recursivo
Cada llamada genera 2 más, formando un árbol gigante de operaciones repetidas.
def fibonacci(n):
if n <= 1:
return n
return fibonacci(n - 1) + fibonacci(n - 2)
# Con n=40 ya tarda varios segundos: el arbol de llamadas explota
fibonacci(10) # -> 55Ejemplo 2 · Generar subconjuntos
Una lista de n elementos tiene exactamente 2ⁿ subconjuntos posibles.
def subconjuntos(lista):
if not lista:
return [[]]
primero = lista[0]
resto = subconjuntos(lista[1:])
return resto + [[primero] + r for r in resto]
# [1,2,3] tiene 2^3 = 8 subconjuntos posibles
subconjuntos([1, 2, 3]) # -> [[], [3], [2], [2,3], [1], [1,3], [1,2], [1,2,3]]Comparación general
Esta tabla muestra cómo escala cada complejidad cuando crecen los datos. Notá la diferencia abismal entre O(log n) y O(2ⁿ) cuando n llega a apenas 1.000.
| Complejidad | n = 10 | n = 100 | n = 1.000 | Cuándo aparece |
|---|---|---|---|---|
| O(1) | 1 | 1 | 1 | Acceso por índice, hash lookup |
| O(log n) | ~3 | ~7 | ~10 | Búsqueda binaria, árboles balanceados |
| O(n) | 10 | 100 | 1.000 | Recorrer una lista |
| O(n²) | 100 | 10.000 | 1.000.000 | Loops anidados, comparar pares |
| O(2ⁿ) | 1.024 | ~10³⁰ | impráctico | Combinatorias, recursión sin memo |
Cierre rápido
Si tenés que recordar Big O en una entrevista o en una review, alcanza con tener clara esta lista mental:
- O(1) Acceso directo. No depende del tamaño de la entrada.
- O(n) Un loop. Recorrés los datos una vez.
- O(log n) Divide y conquista. En cada paso reducís el problema a la mitad.
- O(n²) Loops anidados. Por cada elemento mirás todos los demás.
- O(2ⁿ) Recursión combinatoria. Cada paso multiplica el trabajo.
Conclusión
Big O no es una métrica para "ver cuántos milisegundos tarda mi código". Es un lenguaje para hablar de cómo se va a comportar tu algoritmo cuando los datos crezcan, y para tomar decisiones antes de que el sistema explote en producción.
En resumen: no escribas código que funcione con 10 elementos y muera con 10.000. Pensá siempre cómo escala.